I recently made a post on Twitter/X that I’m going to do one LeetGPU challenge per day and do a write up about my solution and what I learn.
I’m pretty new to GPU programming. I’ve done some shader and game programming before, so I’ve used the GPU here and there, but honestly it never really felt like “real” GPU stuff to me since it was always pretty basic, so for these challenges, I decided to go with Triton. It lets you write GPU kernels in Python and gives you a nice abstraction layer, so you don’t have to dig into all the GPU internals so you can focus more on just building some intuition about how things work.
Once I finish all the challenges, the plan is to redo them all from scratch using CUDA so I can learn that as well.
The Challenge: Vector Addition
The task is pretty simple. We get 2 arrays A and B and we must do element wise addition with them and store the result in C.
Constraints:
- Input vectors A and B have identical lengths
- 1 ≤ N ≤ 100,000,000 elements
Example
Input: A = [1.0, 2.0, 3.0, 4.0] B = [5.0, 6.0, 7.0, 8.0]Output: C = [6.0, 8.0, 10.0, 12.0]Without using the GPU the typical way to solve this would be:
A = [1.0, 2.0, 3.0, 4.0]B = [5.0, 6.0, 7.0, 8.0]C = []for (val_a, val_b) in zip(A, B): C.append(val_a + val_b)# C now contains [6.0, 8.0, 10.0, 12.0]Solving the Challenge
From my limited GPU knowledge I already had a general idea on how to solve this.
The “basic” GPUless solution as we saw earlier was
Read element i from A, B and add them and store in C at index i.
Considering the fact that GPUs have a ton of cores that can all run at the same time it seems like all we need to do is instead of run that solution logic in series one by one, we tell a large amount of cores on the GPU to execute that logic and for each core to work on a different index.
So the goal is to go from the serial CPU way:
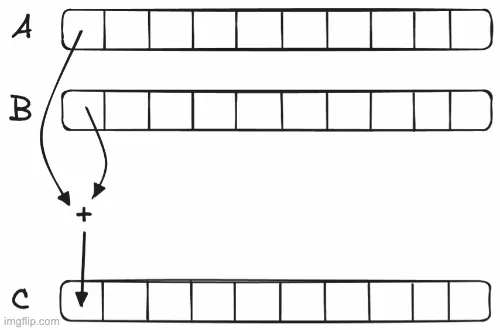
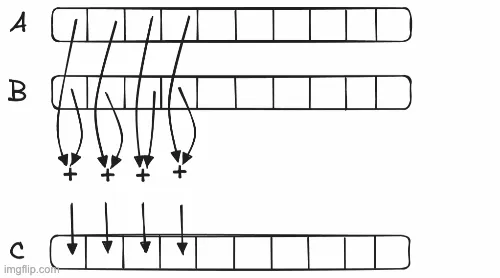
To the parallelized GPU Way (Notice the out of bounds read at the last step? We’ll talk about those soon!):
Note
You can do parallelization in multiple ways on the CPU as well, specially when like in the photos above there’s a very small amount of work to be parallelized (It can be even faster than doing it on the GPU sometimes since there’s overhead to send data over and read back). This illustration is just for demonstration purposes.
Let’s write the pseudo code for what we want!
def sum_on_gpu(A, B, C): # Let's do 4 values at a time THREAD_COUNT = 4 iterations = ceil(len(A) / THREAD_COUNT) for i in range(iteration): gpu_threads = get_gpu_threads(count=THREAD_COUNT) # gpu_threads = [Thread(ID=0), Thread(ID=1), Thread(ID=2), Thread(ID=3)]
# Make each thread read from A and B # At offset = their own thread id into a local variable # We also need to consider the iteration offset = THREAD_COUNT * i gpu_threads.read_value(A, index=THREAD_INDEX + offset, as=a_variable) gpu_threads.read_value(B, index=THREAD_INDEX + offset, as=b_variable)
# Make each thread add the value of their a_variable and b_variable gpu_threads.add(a_variable, b_variable, as=c_variable)
# Make each thread store the value of c_variable # into C at index = their own thread id gpu_threads.store_value(C, index=THREAD_INDEX + offset, value=c_variable)
def main(A, B): # Allocate C with the correct length before calling the GPU to do the task # GPU code should focus on working with preallocated memory C = [0] * len(A) sum_on_gpu(A, B, C)Note
It’s not clear from this pseudocode but another thing you have to be mindful of when writing GPU code is that the GPU and the CPU have different memories (The GPU uses its own dedicated RAM instead of the system wide one). If arrays A, B, and C are on the system wide RAM they must be copied over to the GPU’s memory first. And once the GPU is finished the CPU must read back the answer from the GPU’s memory onto the RAM. If you recall the note from above about it being faster to do some tasks on the CPU even when parallelization can help it’s mostly because of this overhead.
It was my first time writing Triton code so I looked online for tutorials to learn the syntax and figure out how to write the code above with Triton.
While looking around I found out that Triton’s official docs have a tutorials section and the first tutorial is actually on the exact challenge we’re trying to solve! Official Triton Tutorial on Vector Addition. Reading the tutorial along with the comments they added to their code snippets helped me understand the core concepts and after a bit of playing around I was able to write the solution!
The Solution
Now let’s go over writing the solution code to learn the basics of Triton and write our first GPU kernel!
Step 1. Boilerplate
Check out the code below that LeetGPU has already prepared for us when we try to solve the challenge. Let’s dissect it bit by bit.
import torchimport tritonimport triton.language as tl
@triton.jitdef vector_add_kernel(a, b, c, n_elements, BLOCK_SIZE: tl.constexpr): pass
# a, b, c are tensors on the GPUdef solve(a: torch.Tensor, b: torch.Tensor, c: torch.Tensor, N: int): BLOCK_SIZE = 1024 grid = (triton.cdiv(N, BLOCK_SIZE),) vector_add_kernel[grid](a, b, c, N, BLOCK_SIZE)From the top:
@triton.jitmarks the functionvector_add_kernelto tell Triton to JIT compile the function into a GPU kernel so that it can be executed in the GPU. Sovector_add_kernelis where we put our logic from thesum_on_gpufunction in our pseudocode from earlier.# a, b, c are tensors on the GPUtells us that when LeetGPU calls our code witha, b, and cit has already moved them over to the GPU’s memory for us.solveis just a simple python function that does some basic set up for us and then calls the GPU kernel. So it’s basically ourmainfunction from the pseudocode.
Now let’s look inside solve:
Remember how we decided we were going to have 4 threads? This part of the code is where we roughly set that up. And we’re going to have way more threads than 4.
BLOCK_SIZE = 1024grid = (triton.cdiv(N, BLOCK_SIZE),)As you can see there’s no mention of the word “thread” so let’s first talk about what grid and block mean and then we can go back to talking about what’s happening here.
Grids, Blocks and Threads:
In GPU programming, we organize work using grids, blocks and threads. Think of it like this:
- The grid is the collection of all the blocks that execute our kernel
- A block is a group of threads that work together and can share resources easily like their working memory and coordinate much better
- A thread is the single unit that executes logic. In our example it’s what executes our core logic of
Read element i from A, B and add them and store in C at index i
In Triton blocks and threads are abstracted away from us and all we control is the grid,
which launches what Triton calls programs which you can think of as something similar to blocks above (A program can actually be managing multiple blocks under the hood though).
Also this means vector_add_kernel is the logic each program executes.
Now back to what’s happening in the code:
- We set
BLOCK_SIZEto the amount of elements we want each Triton program to handle. In this case1024 - We’re setting
grid = (triton.cdiv(N, BLOCK_SIZE),)as a tuple with 1 element. Think of the grid as a way to give each of our programs an ID they can use to index into the data (Remember how we used to index into the values using thread ids?). - Sometimes the data might be multi dimensional and it’d be much easier if we could give our programs an X,Y,Z ID instead of a single ID. In those cases you can set the grid to have multiple elements. Since we’re dealing with vectors here and they only have 1 dimension we just set grid to have 1 element so our programs can just have a single ID.
triton.cdiv(N, BLOCK_SIZE)does ceiling division. By using it to specify the grid size we’re basically saying we wantceil(N / BLOCK_SIZE)programs to be run. IfNis 5000 andBLOCK_SIZEis 1024, we getceil(5000/1024) = 5programs each handling 1024 elements which would be enough to handle the 5000 elements.- Program 0 handles elements 0-1023
- Program 1 handles elements 1024-2047
- Program 2 handles elements 2048-3071
- Program 3 handles elements 3072-4095
- Program 4 handles elements 4096-5119 (We will have to somehow skip 5000-5119 to prevent out of bounds memory access)
Inside each program when executing your code Triton vectorizes execution (i.e. automatically parallelizes execution and handles the blocks / threads for you. For example if you give it [1, 2, 3] + [4, 5, 6] it will use 3 threads each adding one element).
Step 2. Loading values
Let’s implement vector_add_kernel so each program can load the proper values from A and B to be able to add them.
@triton.jitdef vector_add_kernel(a, b, c, n_elements, BLOCK_SIZE: tl.constexpr): pid = tl.program_id(axis=0) offset = pid * BLOCK_SIZE indices = tl.arange(0, BLOCK_SIZE) + offset mask = indices < n_elements x = tl.load(a + indices, mask=mask) y = tl.load(b + indices, mask=mask)From the top:
tl.program_id(axis=0)gives us the ID of the program. We useaxis=0since if you remember our grid only has one element and our program IDs are one dimensional. If we had more dimensions we could read them individually astl.program_id(axis=0)andtl.program_id(axis=1).- We calculate
offset = pid * BLOCK_SIZEso we can index into the arrays properly. In this case since each program handles 1024 elements for example, we’d want program with ID=1 to handle elements starting from 1024 since 0..1023 would be handled by ID=0 so we do pid (=1) * 1024. tl.arange(0, BLOCK_SIZE)gives us array[0..BLOCK_SIZE - 1]- We use
indices = tl.arange(0, BLOCK_SIZE) + offsetto set up the indices we want to access in our input arrays in each program. In our ID=1 example this would be[0..1023] + 1024. This does something called “broadcasting” where every single element in the array gets+ 1024. So it becomes [1024..2047]. Keep in mind, since this is done in Triton it automatically does this with parallelization so you can imagine in one step every single one of those elements got the addition done. - Remember the issue we had with out of bounds access? We handle that using
mask = indices < n_elements. We create a mask array (Since it’sarray < intit utilizes broadcasting) where it has the same element count asindicesand wherever the value inindicesis bigger thann_elementswhich would lead to an out of bounds read it has afalse - We use
tl.load(a + indices, mask=mask)to load values from array A so we can work on them.a + indicessays take the pointer of array A (start position of array A in memory) +array of indexessince again this is a single value + array, it does broadcasting and we end up with an array where each element is a position in the GPU memory andmask=masksays for each element of that array if the corresponding element in this mask is false do not perform a read since it’s out of bounds. - Same as above with
tl.load(b + indices, mask=mask)
Step 3. Addition and Storage
The hard part is over! We have everything we need. Now we just need to add the values we loaded and put them in C.
@triton.jitdef vector_add_kernel(a, b, c, n_elements, BLOCK_SIZE: tl.constexpr): pid = tl.program_id(axis=0) offset = pid * BLOCK_SIZE indices = tl.arange(0, BLOCK_SIZE) + offset mask = indices < n_elements x = tl.load(a + indices, mask=mask) y = tl.load(b + indices, mask=mask) result = x + y tl.store(c + indices, result, mask=mask)- We calculate the addition using
result = x + yand add the values we just loaded from A and B. This is basically like doing[1, 2, 3, 4] + [5, 6, 7, 8]. Also if you remember from above about Triton vectorizing execution, you can see that this is going to be done in parallel and is efficient. - We store the result using
tl.store(c + indices, result, mask=mask). This works exactly the same as howtl.loadworked from above except it accepts an array to know what values to put there.
Step 4. Final Code
We’re done! Here’s the final code :)
import torchimport tritonimport triton.language as tl
@triton.jitdef vector_add_kernel(a, b, c, n_elements, BLOCK_SIZE: tl.constexpr): pid = tl.program_id(axis=0) offset = pid * BLOCK_SIZE indices = tl.arange(0, BLOCK_SIZE) + offset mask = indices < n_elements x = tl.load(a + indices, mask=mask) y = tl.load(b + indices, mask=mask) result = x + y tl.store(c + indices, result, mask=mask)
# a, b, c are tensors on the GPUdef solve(a: torch.Tensor, b: torch.Tensor, c: torch.Tensor, N: int): BLOCK_SIZE = 1024 grid = (triton.cdiv(N, BLOCK_SIZE),) vector_add_kernel[grid](a, b, c, N, BLOCK_SIZE)What’s Next
I’ll be posting more challenges as I work through them! My goal is 1 per day but writing this blog post made me realize how time consuming it is to write so I might take longer, sorry 😅